|
文章目录
KNNSVM朴素贝叶斯决策树随机森林
KNN
“近朱者赤,近墨者黑”可以说是 KNN 的工作原理。 整个计算过程分为三步:
计算待分类物体与其他物体之间的距离;统计距离最近的 K 个邻居;对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类。
说说向量的距离。在KNN和其他机器学习算法中,常用的距离计算公式包括欧氏距离和曼哈顿距离。两个向量之间,用不同的距离计算公式得出来的结果是不一样的。
欧氏距离是欧几里得空间中两点间的“普通”(即直线)距离。在欧几里得空间中,点x=(x1, … ,xn)和点y=(y1, … ,yn)之间的欧氏距离为: 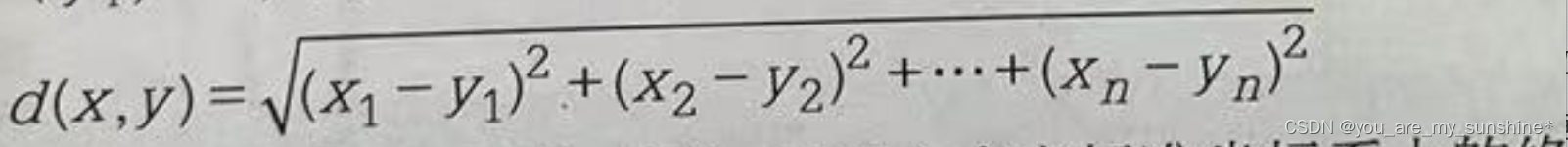
曼哈顿距离,也叫方格线距离或城市区块距离,是两个点在标准坐标系上的绝对轴距的总和。!在欧几里得空间的固定直角坐标系上,曼哈顿距离的意义为两点所形成的线段对轴产生的投影的距离总和。在平面上,点x=(xi,.,!x.)和点y=(yi,.,yn)之间的曼哈顿距离为: 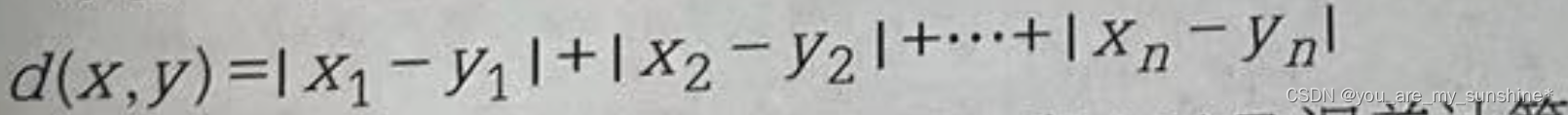
下图的两个点之间,1、2与3线表示的各种曼哈顿距离长度都相同,而4线表示的则是欧氏距离。 
下图中的两个特征,就形成了二维空间,图中心的问号代表一个未知类别的样本。如何归类呢,它是圆圈还是叉号?如果K=3,叉号所占比例大,问号样本将被判定为叉号类;如果K=7.则圆圈所占比例大,问号样本将被判定为圆圈类。
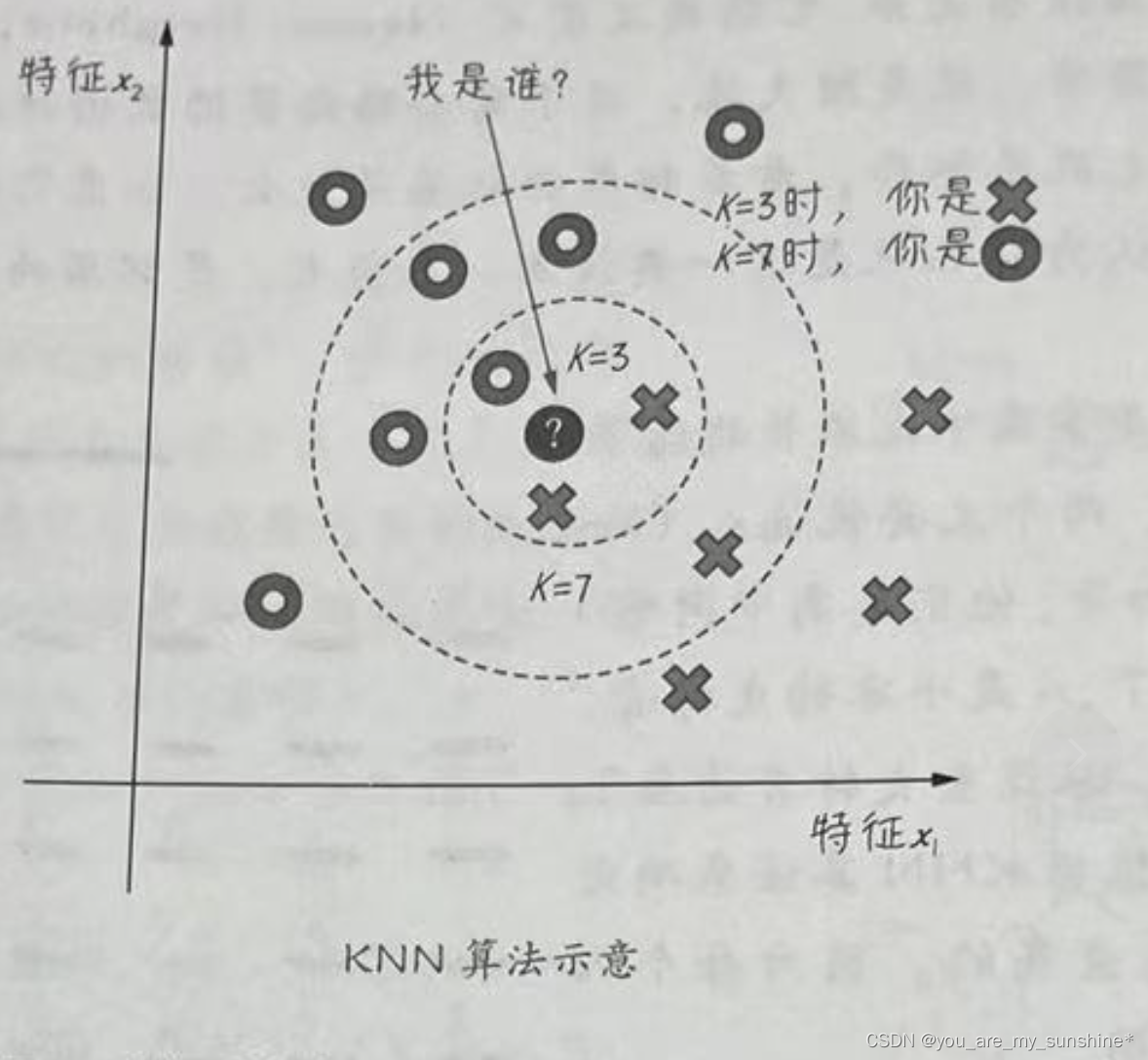
因此,KNN算法的结果和K的取值有关系。要注意的是,KNN要找的邻居都是已经“站好队的人”,也就是已经正确分类的对象。
SVM
用 SVM 计算的过程就是帮我们找到那个超平面的过程,这个超平面就是我们的 SVM 分类器。
主要说说超平面(hyperplane)和支持向量( support vector)这两个概念。超平面,就是用于特征空间根据数据的类别切分出来的分界平面。如下图所示的两个特征的二分类问题,我们就可以用一条线来表示超平面。如果特征再多一维,可以想象切割线会延展成一个平面,以此类推。而支持向量,就是离当前超平面最近的数据点,也就是下图中被分界线的两条平行线所切割的数据点,这些点对于超平面的进一步确定和优化最为重要。
如下图所示,在一个数据集的特征空间中,存在很多种可能的类分割超平面。比如,图中的H0实线和两条虚线,都可以把数据集成功地分成两类。 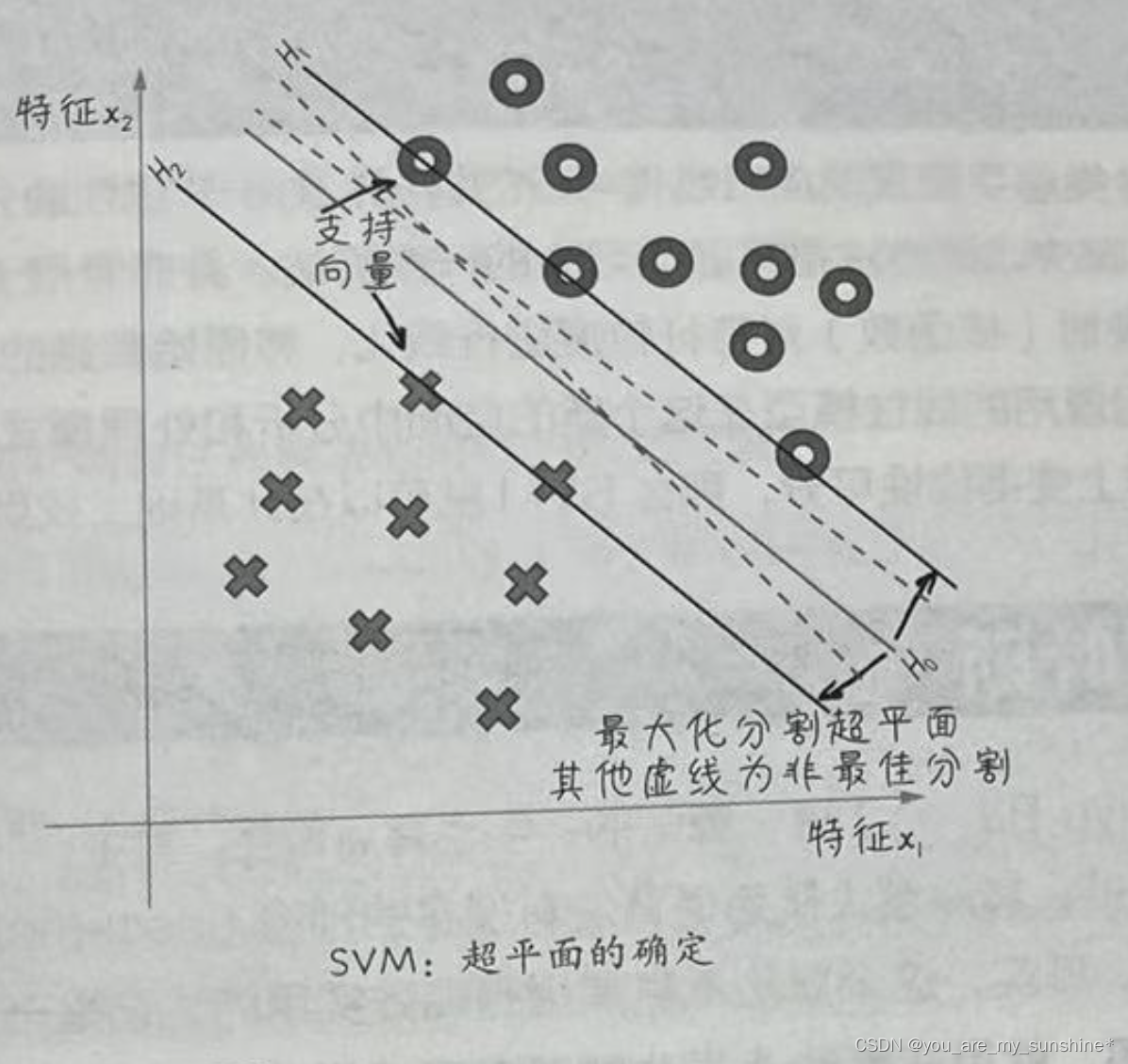
是实线分割较好,因为这样的分界线离两个类中的支持向量都比较远。SVM算法就是要在支持向量的帮助之下,通过类似于梯度下降的优化方法,找到最优的分类超平面——具体的目标就是令支持向量到超平面之间的垂直距离最宽,称为“最宽街道”。
那么目前的特征空间中有以下3条线。
H0就是目前的超平面。与之平行的H1H₂线上的特征点就是支持向量。 这3条线,由线性函数和其权重、偏置的值所确定:  然后计算支持向量到超平面的垂直距离,并通过机器学习算法调整参数w和b,将距离(也就是特征空间中的这条街道宽度)最大化。这和线性回归寻找最优函数的斜率和截距的过程很相似。 然后计算支持向量到超平面的垂直距离,并通过机器学习算法调整参数w和b,将距离(也就是特征空间中的这条街道宽度)最大化。这和线性回归寻找最优函数的斜率和截距的过程很相似。
普通的SVM分类超平面只能应对线性可分的情况,对于非线性的分类,SVM要通过核方法( kernel method)解决。核方法是机器学习中的一类算法,并非专用于SVM。它的思路是,首先通过某种非线性映射(核函数)对特征粒度进行细化,将原始数据的特征嵌入合适的更高维特征空间;然后,利用通用的线性模型在这个新的空间中分析和处理模式,这样,将在二维上线性不可分的问题在多维上变得线性可分,那么SVM就可以在此基础上找到最优分割超平面。
朴素贝叶斯
朴素贝叶斯是一个通过条件概率进行分类的算法。
所谓条件概率,就是在事件A发生的概率下B发生的概率。例如,男生(事件A)是烟民(事件B)的概率为30%,女生(事件A)是烟民(事件B)的概率为5%。这些事件A就是“已发生的事件”,也就是所谓“预设”,也就是条件。
那么如何把条件概率引入机器学习呢?可以这么理解:数据集中数据样本的特征就形成了条件事件。比如:男,80岁,血压150mmHg,这3个已发生的事件,就是样本已知的特征。下面就需要进行二分类,确定患病还是未患病。此时我们拥有的信息量不多,怎么办呢?看一下训练数据集中满足这3个条件的数据有多少个,然后计算概率和计算分布。假如还有3个同样是80岁的男人,血压也是150mmHg,两个有心脏病,一个健康。此时算法就告诉我们,应该判断这个人也有心脏病的概率比较大。如果没有其他血压读数刚好是150的人呢?那就看看其他80岁的男人。如果10个人里面6个人都有心脏病,我们也只好推断此人有心脏病。 这就是朴素贝叶斯的基本原理。它会假设每个特征都是相互独立的(这就是一个很强的预设),然后计算每个类别下的各个特征的条件概率。条件概率的公式如下:
在机器学习实践中,可以将上面的公式拆分成多个具体的特征:
公式解释如下。 Ck,代表的是分类的具体类别k。 P(c|x)是条件概率,也就是所要计算的,当特征为x时,类别为c的概率。 P(x l c)叫作似然(likelihood),就是训练集中标签分类为c的情况下,特征为x的概率。 比如,在垃圾电子邮件中,文本中含有“幸运抽奖”这个词的概率为0.2,换句话说,这个“0.2” 也就是“幸运抽奖”这个词出现在垃圾电子邮件中的似然。 P©,是训练集中分类为C的先验概率。比如,全部电子邮件中,垃圾电子邮件的概率为0.1。 P(x),是特征的先验概率。
为什么图中这两个公式不大一样,第二个公式没有P(x)了。 因为在实践中,这个分母项在计算过程中会被忽略。因为这个P(x),不管它的具体值多大,具体到一个特征向量,对于所有的分类e来说,这个值其实是固定的一并不随中K值的变化而改变。因此它是否存在,并不影响一个特定数据样本的归类。机器最后要做的,只是确保所求出的所有类的后验概率之和为1。这可以通过增加一个归一化参数 实现。
基本上,朴素贝叶斯是基于现有特征的概率对输入进行分类的,它的速度相当快,当没有太多数据并且需要快速得到结果时,朴素贝叶斯算法可以说是解决分类问题的良好选择。
决策树
这个算法简单直观,很容易理解。它有点像是将一大堆的if… else 语句进行连接,直到最后得到想要的结果。算法中的各个节点是根据训练数据集中的特征形成的。大家要注意特征节点的选择不同时,可以生成很多不一样的决策树。” “下图所示是一个相亲数据集和根据该数据集而形成的决策树。此处我们设定一个根节点,作为决策的起点,从该点出发,根据数据集中的特征和标签值给树分叉。” 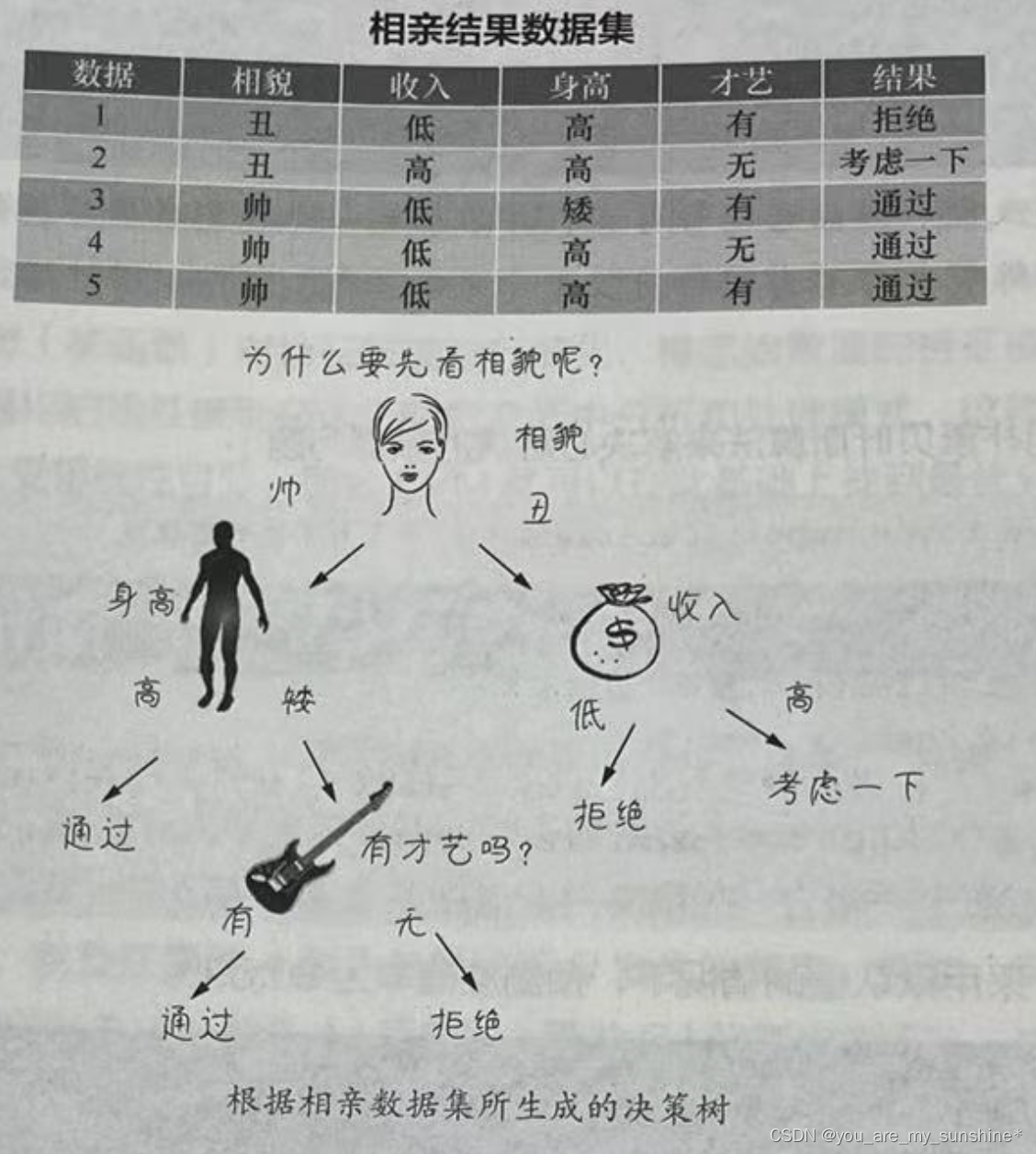
为什么要选择相貌这个特征作为这棵决策树的根节点?,是因为熵。
在信息学中,熵(entropy),度量着信息的不确定性,信息的不确定性越大,熵越大。信息熵和事件发生的概率成反比。比如,“相亲者会认为这位先生很帅”这一句话的信息熵为0,因为这是事实。
这里有几个新概念,下面介绍一下。
信息熵代表随机变量的复杂度,也就是不确定性。条件熵代表在某一个条件下,随机变量的复杂度。信息增益等于信息熵减去条件熵,它代表了在某个条件下,信息复杂度(不确定性)减少的程度。
因此,如果一个特征从不确定到确定,这个过程对结果影响比较大的话,就可以认为这个特征的分类能力比较强。那么先根据这个特征进行决策之后,对于整个数据集而言,熵(不确定性)减少得最多,也就是信息增益最大。相亲的时候你们最看中什么,就先问什么,如果先问相点,说明你们觉得相貌不合格则后面其他所有问题都不用再问了,当然你们的妈妈可能一般会先问收入。
除了熵之外,还有Gini不纯度等度量信息不确定性的指标。
决策树的深度和剪枝 决策树算法有以下两个特点。 (1)由于if…else可以无限制地写下去,因此,针对任何训练集,只要树的深度足够,决策树肯定能够达到100%的准确率。这听起来像是个好消息。 (2)决策树非常容易过拟合。也就是说,在训练集上,只要分得足够细,就能得到100%的正确结果,然而在测试集上,准确率会显著下降。 这种过拟合的现象在下图的这个二分类问题中就可以体现出来。决策树算法将每一个样本都根据标签值成功分类,图中的两种颜色就显示出决策树算法生成的分类边界。
而实际上,当分类边界精确地绕过了每一个点时,过拟合已经发生了。根据直觉,那个被圆圈包围着的叉号并不需要被考虑,它只是一个特例。因此,树的最后几个分叉,也就是找到虚线框内叉号的决策过程都应该省略,才能够提高模型的泛化功能。解决的方法是为决策树进行剪枝(pruning),有以下两种形式。
先剪枝:分支的过程中,熵减少的量小于某一个阈值时,就停止分支的创建。后剪枝:先创建出完整的决策树,然后尝试消除多余的节点。
整体来说,决策树算法很直观,易于理解,因为它与人类决策思考的习惯是基本契合的,而且模型还可以通过树的形式可视化。此外,决策树还可以直接处理非数值型数据,不需要进行哑变量的转化,甚至可以直接处理含缺失值的数据。因此,决策树算法是应用较为广泛的算法。
然而,它的缺点明显。首先,对于多特征的复杂分类问题效率很一般,而且容易过拟合。节点很深的树容易学习到高度不规则的模式,造成较大的方差,泛化能力弱。此外,决策树算法处理连续变量问题时效果也不太好。
因为这些缺点,决策树很少独立作为一种算法被应用于实际问题。然而,一个非常微妙的事是,决策树经过集成的各种升级版的算法一随机森林、梯度提升树算法等,都是非常优秀的常用算法。
随机森林
随机森林(random forest)是一种健壮且实用的机器学习算法,它是在决策树的基础上衍生而成的。决策树和随机森林的关系就是树和森林的关系。通过对原始训练样本的抽样,以及对特征节点的选择,我们可以得到很多棵不同的树。 刚才说到决策树很容易过拟合,而随机森林的思路是把很多棵决策树的结果集成起来,以避免过拟合,同时提高准确率。其中,每一棵决策树都是在原始数据集中抽取不同子集进行训练的,尽管这种做法会小幅度地增加每棵树的预测偏差,但是最终对各棵树的预测结果进行综合平均之后的模型性能通常会大大提高。 这就是随机森林算法的核心:或许每棵树都是一个非常糟糕的预测器,但是当我们将很多棵树的预测集中在一起考量时,很有可能会得到一个好的模型。 假设我们有一个包含N个训练样本的数据集,特征的维度为M,随机森林通过下面算法构造树。 (1)从N个训练样本中以有放回抽样(replacement sampling)的方式,取样N次,形成一个新训练集(这种方法也叫bootstrap取样),可用未抽到的样本进行预测,评估其误差。 (2)对于树的每一个节点,都随机选择m个特征(m是M的一个子集,数目远小于M),决策树上每个节点的决定都只是基于这些特征确定的,即根据这m个特征,计算最佳的分裂方式。 (3)默认情况下,每棵树都会完整成长而不会剪枝。 上述算法有两个关键点:一个是有放回抽样,二是节点生成时不总是考量全部特征。这两个关键点,都增加了树生成过程中的随机性,从而降低了过拟合。 仅引入了一点小技巧,就形成了如此强大的随机森林算法。这就是算法之美,是机器学习之美。 在Skleam 的随机森林分类器中,可以设定的一些的参数项如下。
n_estimators:要生成的树的数量。criterion :信息增益指标,可选择gini(Gini不纯度)或者entropy(熵)。bootstrap :可选择是否使用bootstrap方法取样,True或者False。如果选择False,则所有树都基于原始数据集生成。max_features:通常由算法默认确定。对于分类问题,默认值是总特征数的平方根,即如果一共有9个特征,分类器会随机选取其中3个。
import numpy as np #导入NumPy数学工具箱
import pandas as pd #导入Pandas数据处理工具箱
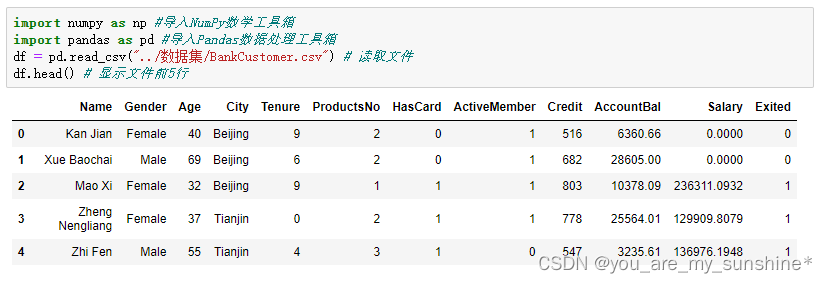
df = pd.read_csv("../数据集/BankCustomer.csv") # 读取文件
df.head() # 显示文件前5行
# 构建特征和标签集
y = df.Exited.values
X = df.drop(['Exited'], axis = 1)
from sklearn.model_selection import train_test_split # 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2,random_state=0)
# 进行特征缩放
from sklearn import preprocessing
scaler = preprocessing.MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
from sklearn.metrics import (f1_score, confusion_matrix) # 导入评估指标
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
from sklearn.metrics import f1_score, confusion_matrix # 导入评估标准
lr = LogisticRegression() # 逻辑回归
lr.fit(X_train,y_train) # 训练模型
y_pred = lr.predict(X_test) # 预测结果
lr_acc = lr.score(X_test,y_test)*100 # 准确率
lr_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("逻辑回归测试集准确率: {:.2f}%".format(lr_acc))
print("逻辑回归测试集F1分数: {:.2f}%".format(lr_f1))
print('逻辑回归测试集混淆矩阵:\n', confusion_matrix(y_test,y_pred))

from sklearn.neighbors import KNeighborsClassifier # 导入KNN算法
k = 5 # 设定初始K值为5
knn = KNeighborsClassifier(n_neighbors = k) # KNN模型
knn.fit(X_train, y_train) # 拟合KNN模型
y_pred = knn.predict(X_test) # 预测结果
knn_acc = knn.score(X_test,y_test)*100 # 准确率
knn_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("{}NN 预测准确率: {:.2f}%".format(k, knn_acc))
print("{}NN 预测F1分数: {:.2f}%".format(k, knn_f1))
print('KNN 混淆矩阵:\n', confusion_matrix(y_test,y_pred))

from sklearn.svm import SVC # 导入SVM分类器
svm = SVC(random_state = 1) # SVM模型
svm.fit(X_train, y_train) #拟合SVM模型
y_pred = svm.predict(X_test) # 预测结果
svm_acc = svm.score(X_test,y_test)*100 # 准确率
svm_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("SVM 预测准确率:: {:.2f}%".format(svm_acc))
print("SVM 预测F1分数: {:.2f}%".format(svm_f1))
print('SVM 混淆矩阵:\n', confusion_matrix(y_test,y_pred))

from sklearn.naive_bayes import GaussianNB # 导入模型
nb = GaussianNB() # 朴素贝叶斯模型
nb.fit(X_train, y_train) # 拟合模型
y_pred = nb.predict(X_test) # 预测结果
nb_acc = nb.score(X_test,y_test)*100 # 准确率
nb_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("朴素贝叶斯测试集准确率:: {:.2f}%".format(nb_acc))
print("朴素贝叶斯测试集F1分数: {:.2f}%".format(nb_f1))
print('朴素贝叶斯混淆矩阵:\n', confusion_matrix(y_test,y_pred))

from sklearn.tree import DecisionTreeClassifier # 导入模型
dt = DecisionTreeClassifier() # 分类决策树
dt.fit(X_train, y_train) # 拟合模型
y_pred = dt.predict(X_test) # 预测结果
dt_acc = dt.score(X_test,y_test)*100 # 准确率
dt_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("决策树测试集准确率:: {:.2f}%".format(dt_acc))
print("决策树测试集F1分数: {:.2f}%".format(dt_f1))
print('决策树混淆矩阵:\n', confusion_matrix(y_test,y_pred))

from sklearn.ensemble import RandomForestClassifier # 导入模型
rf = RandomForestClassifier(n_estimators = 1000, random_state = 1) # 随机森林
rf.fit(X_train, y_train) # 拟合模型
y_pred = rf.predict(X_test) # 预测结果
rf_acc = rf.score(X_test,y_test)*100 # 准确率
rf_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("随机森林 预测准确率:: {:.2f}%".format(rf_acc))
print("随机森林 预测F1分数: {:.2f}%".format(rf_f1))
print('随机森林 混淆矩阵:\n', confusion_matrix( y_test,y_pred))

from xgboost import XGBClassifier
xgb = XGBClassifier()
xgb.fit(X_train, y_train) # 拟合模型
y_pred = xgb.predict(X_test) # 预测结果
xgb_acc = xgb.score(X_test,y_test)*100 # 准确率
xgb_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("XGB 预测准确率:: {:.2f}%".format(xgb_acc))
print("XGB 预测F1分数: {:.2f}%".format(xgb_f1))
print('XGB 混淆矩阵:\n', confusion_matrix( y_test,y_pred))

from xgboost import XGBClassifier
xgb_c = XGBClassifier(max_depth=6, learning_rate=0.05, n_estimators=2000,
objective='binary:logistic', tree_method='hist',
subsample=0.8, colsample_bytree=0.8,
min_child_samples=3, eval_metric='auc', reg_lambda=0.5)
#hist之前是gpu_hist,gpu_hist是需要用到gpu,而我们没有,所以去掉gpu
xgb_c.fit(X_train, y_train)
y_pred = xgb_c.predict(X_test)
xgb_c_acc = xgb_c.score(X_test,y_test)*100 # 准确率
xgb_c_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("xgb_c 预测准确率:: {:.2f}%".format(xgb_c_acc))
print("xgb_c 预测F1分数: {:.2f}%".format(xgb_c_f1))
print('xgb_c 混淆矩阵:\n', confusion_matrix( y_test,y_pred))

from lightgbm import LGBMClassifier
lgb = LGBMClassifier()
lgb.fit(X_train, y_train) # 拟合模型
y_pred = lgb.predict(X_test) # 预测结果
lgb_acc = lgb.score(X_test,y_test)*100 # 准确率
lgb_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("LGB 预测准确率:: {:.2f}%".format(lgb_acc))
print("LGB 预测F1分数: {:.2f}%".format(lgb_f1))
print('LGB 混淆矩阵:\n', confusion_matrix( y_test,y_pred))

from lightgbm import LGBMClassifier
lgb_c = LGBMClassifier(num_leaves=2**5-1, reg_alpha=0.25, reg_lambda=0.25,
objective='binary',max_depth=-1, learning_rate=0.005,
min_child_samples=3, random_state=2021,
n_estimators=2000, subsample=1, colsample_bytree=1)
lgb_c.fit(X_train, y_train) # 拟合模型
y_pred = lgb_c.predict(X_test) # 预测结果
lgb_c_acc = lgb_c.score(X_test,y_test)*100 # 准确率
lgb_c_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("lgb_c 预测准确率:: {:.2f}%".format(lgb_c_acc))
print("lgb_c 预测F1分数: {:.2f}%".format(lgb_c_f1))
print('lgb_c 混淆矩阵:\n', confusion_matrix( y_test,y_pred))

from catboost import CatBoostClassifier
cat = CatBoostClassifier()
cat.fit(X_train, y_train) # 拟合模型
y_pred = cat.predict(X_test) # 预测结果
cat_acc = cat.score(X_test,y_test)*100 # 准确率
cat_f1 = f1_score(y_test, y_pred)*100 # F1分数
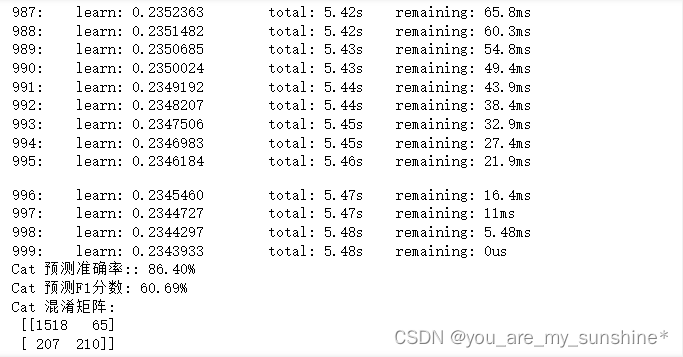
print("Cat 预测准确率:: {:.2f}%".format(cat_acc))
print("Cat 预测F1分数: {:.2f}%".format(cat_f1))
print('Cat 混淆矩阵:\n', confusion_matrix( y_test,y_pred))
from catboost import CatBoostClassifier
cat_c = CatBoostClassifier(iterations=1000, #最大树数,即迭代次数
depth = 6, #树的深度
learning_rate = 0.03, #学习率
custom_loss='AUC', #训练过程中,用户自定义的损失函数
eval_metric='AUC', #过拟合检验(设置True)的评估指标,用于优化
bagging_temperature=0.83, #贝叶斯bootstrap强度设置
rsm = 0.78, #随机子空间
od_type='Iter', #过拟合检查类型
od_wait=150, #使用Iter时,表示达到指定次数后,停止训练
metric_period = 400, #计算优化评估值的频率
l2_leaf_reg = 5, #l2正则参数
thread_count = 20, #并行线程数量
random_seed = 967 #随机数种子
)
cat_c.fit(X_train, y_train)
y_pred = cat_c.predict(X_test)
cat_c_acc = cat_c.score(X_test,y_test)*100 # 准确率
cat_c_f1 = f1_score(y_test, y_pred)*100 # F1分数
print("cat_c 预测准确率:: {:.2f}%".format(cat_c_acc))
print("cat_c 预测F1分数: {:.2f}%".format(cat_c_f1))
print('cat_c 混淆矩阵:\n', confusion_matrix(y_test,y_pred))

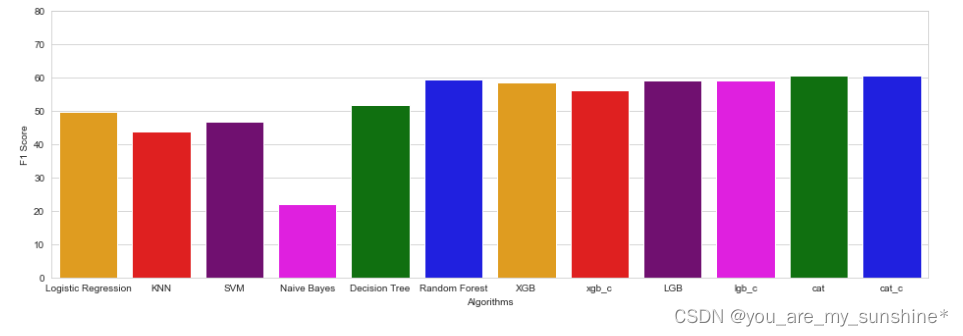
# 用直方图显示出各个算法的F1分数
import seaborn as sns
methods = ["Logistic Regression", "KNN", "SVM", "Naive Bayes", "Decision Tree",
"Random Forest", "XGB", "xgb_c","LGB", "lgb_c", "cat", "cat_c"]
f1 = [lr_f1, knn_f1, svm_f1, nb_f1, dt_f1, rf_f1, xgb_f1, xgb_c_f1, lgb_f1, lgb_c_f1, cat_f1, cat_c_f1]
colors = ["orange","red","purple", "magenta", "green","blue"]
sns.set_style("whitegrid")
plt.figure(figsize=(16,5))
plt.yticks(np.arange(0,100,10))
plt.ylim((0,80))
plt.ylabel("F1 Score")
plt.xlabel("Algorithms")
sns.barplot(x=methods, y=f1, palette=colors)
# plt.grid(b=None)
plt.show()
# 用直方图显示出各个算法的F1分数 实现数值功能
import seaborn as sns
methods_f1 = pd.DataFrame()
methods_f1['methods'] = ["Logistic Regression", "KNN", "SVM", "Naive Bayes", "Decision Tree",
"Random Forest", "XGB", "xgb_c","LGB", "lgb_c", "cat", "cat_c"]
methods_f1['f1'] = [lr_f1, knn_f1, svm_f1, nb_f1, dt_f1, rf_f1, xgb_f1, xgb_c_f1, lgb_f1, lgb_c_f1, cat_f1, cat_c_f1]
colors = ["orange","red","purple", "magenta", "green","blue"]
sns.set_style("whitegrid")
plt.figure(figsize=(16,5))
plt.yticks(np.arange(0,100,10))
plt.ylim((0,80))
plt.ylabel("F1 Score")
plt.xlabel("Algorithms")
g = sns.barplot(x="methods", y="f1", data=methods_f1, palette=colors)
for index, row in methods_f1.iterrows():
# 第一个参数代表第几个柱子
# 第二个参数就传柱子代表的数量,相当于柱子的长度
g.text(index, row.f1, round(row.f1, 2), color="black", ha="center", fontsize=24)
# plt.grid(b=None)
plt.show()
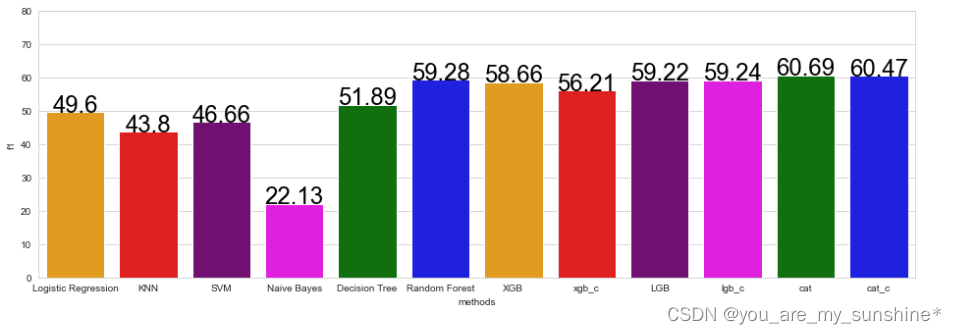
# 用直方图显示出各个算法的预测准确率
import seaborn as sns
methods = ["Logistic Regression", "KNN", "SVM", "Naive Bayes", "Decision Tree",
"Random Forest", "XGB", "xgb_c","LGB", "lgb_c", "cat", "cat_c"]
acc = [lr_acc, knn_acc, svm_acc, nb_acc, dt_acc, rf_acc, xgb_acc, xgb_c_acc, lgb_acc, lgb_c_acc, cat_acc, cat_c_acc]
colors = ["orange","red","purple", "magenta", "green","blue"]
sns.set_style("whitegrid")
plt.figure(figsize=(16,5))
plt.yticks(np.arange(0,100,10))
plt.ylim((60,100))
plt.ylabel("Accurancy %")
plt.xlabel("Algorithms")
sns.barplot(x=methods, y=acc, palette=colors)
# plt.grid(b=None)
plt.show()
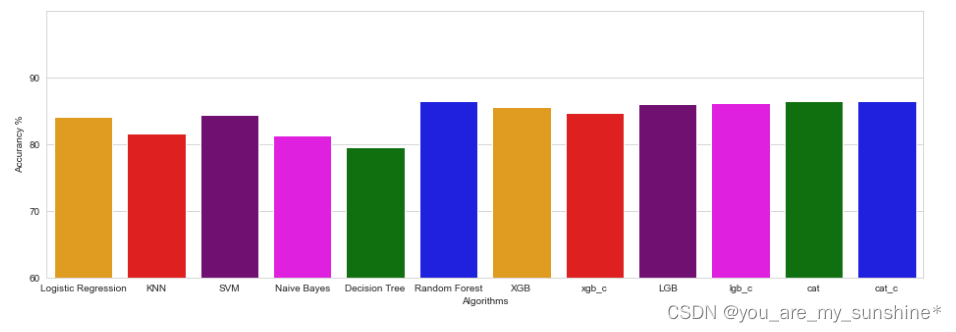
# 用直方图显示出各个算法的预测准确率
import seaborn as sns
methods_acc = pd.DataFrame()
methods_acc['methods'] = ["Logistic Regression", "KNN", "SVM", "Naive Bayes", "Decision Tree",
"Random Forest", "XGB", "xgb_c","LGB", "lgb_c", "cat", "cat_c"]
methods_acc['acc'] = [lr_acc, knn_acc, svm_acc, nb_acc, dt_acc, rf_acc, xgb_acc, xgb_c_acc, lgb_acc, lgb_c_acc, cat_acc, cat_c_acc]
colors = ["orange","red","purple", "magenta", "green","blue"]
sns.set_style("whitegrid")
plt.figure(figsize=(16,5))
plt.yticks(np.arange(0,100,10))
plt.ylim((60,100))
plt.ylabel("Accurancy %")
plt.xlabel("Algorithms")
g = sns.barplot(x='methods', y='acc', palette=colors, data=methods_acc)
for index, row in methods_acc.iterrows():
# 第一个参数代表第几个柱子
# 第二个参数就传柱子代表的数量,相当于柱子的长度
g.text(index, row.acc, round(row.acc, 2), color='black', ha='center', fontsize=24)
# plt.grid(b=None)
plt.show()
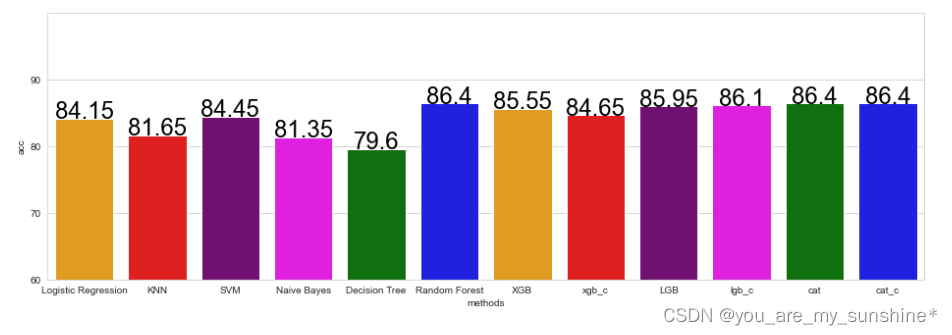
# 绘制各算法的混淆矩阵
from sklearn.metrics import confusion_matrix
plt.rcParams['font.sans-serif'] = 'SimHei'
y_pred_lr = lr.predict(X_test)
kNN5 = KNeighborsClassifier(n_neighbors = 5)
kNN5.fit(X_train, y_train)
y_pred_kNN5 = kNN5.predict(X_test)
y_pred_svm = svm.predict(X_test)
y_pred_nb = nb.predict(X_test)
y_pred_dt = dt.predict(X_test)
y_pred_rf = rf.predict(X_test)
y_pred_xgb = xgb.predict(X_test)
y_pred_xgb_c = xgb_c.predict(X_test)
y_pred_lgb = lgb.predict(X_test)
y_pred_lgb_c = lgb_c.predict(X_test)
y_pred_cat = cat.predict(X_test)
y_pred_cat_c = cat_c.predict(X_test)
cm_lr = confusion_matrix(y_test,y_pred_lr)
cm_kNN5 = confusion_matrix(y_test,y_pred_kNN5)
cm_svm = confusion_matrix(y_test,y_pred_svm)
cm_nb = confusion_matrix(y_test,y_pred_nb)
cm_dt = confusion_matrix(y_test,y_pred_dt)
cm_rf = confusion_matrix(y_test,y_pred_rf)
cm_xgb = confusion_matrix(y_test,y_pred_xgb)
cm_xgb_c = confusion_matrix(y_test,y_pred_xgb_c)
cm_lgb = confusion_matrix(y_test,y_pred_lgb)
cm_lgb_c = confusion_matrix(y_test,y_pred_lgb_c)
cm_cat = confusion_matrix(y_test,y_pred_cat)
cm_cat_c = confusion_matrix(y_test,y_pred_cat_c)
plt.figure(figsize=(24,12))
plt.suptitle("Confusion Matrixes",fontsize=24)
plt.subplots_adjust(wspace = 0.4, hspace= 0.4)
plt.subplot(4,3,1)
plt.title("Logistic Regression Confusion Matrix", fontsize= 21)
sns.heatmap(cm_lr,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,2)
plt.title("K Nearest Neighbors Confusion Matrix", fontsize= 21)
sns.heatmap(cm_kNN5,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,3)
plt.title("Support Vector Machine Confusion Matrix", fontsize= 21)
sns.heatmap(cm_svm,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,4)
plt.title("Naive Bayes Confusion Matrix", fontsize= 21)
sns.heatmap(cm_nb,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,5)
plt.title("Decision Tree Classifier Confusion Matrix", fontsize= 21)
sns.heatmap(cm_dt,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,6)
plt.title("Random Forest Confusion Matrix", fontsize= 21)
sns.heatmap(cm_rf,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,7)
plt.title("XGBClassifier Confusion Matrix", fontsize= 21)
sns.heatmap(cm_xgb,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,8)
plt.title("XGBClassifier_祖传参数 Confusion Matrix", fontsize= 21)
sns.heatmap(cm_xgb_c,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,9)
plt.title("LGBMClassifier Confusion Matrix", fontsize= 21)
sns.heatmap(cm_lgb,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,10)
plt.title("LGBMClassifier_祖传参数 Confusion Matrix", fontsize= 21)
sns.heatmap(cm_lgb_c,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,11)
plt.title("CatBoostClassifier Confusion Matrix", fontsize= 21)
sns.heatmap(cm_cat,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.subplot(4,3,12)
plt.title("CatBoostClassifier_祖传参数 Confusion Matrix", fontsize= 21)
sns.heatmap(cm_cat_c,annot=True,cmap="Blues",fmt="d",cbar=False, annot_kws={"size":28})
plt.show()
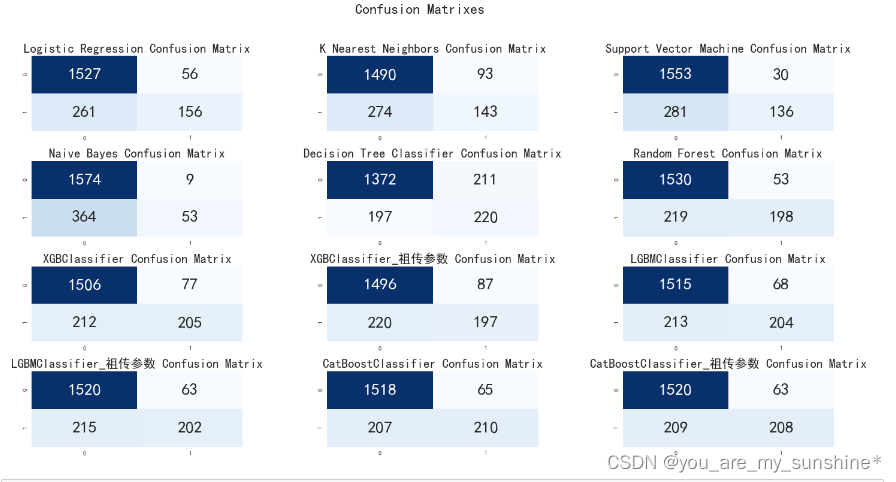
学习机器学习的参考资料: (1)书籍 利用Python进行数据分析 西瓜书 百面机器学习 机器学习实战 阿里云天池大赛赛题解析(机器学习篇) 白话机器学习中的数学 零基础学机器学习 图解机器学习算法 …
(2)机构 光环大数据 开课吧 极客时间 七月在线 深度之眼 贪心学院 拉勾教育 博学谷 …
|